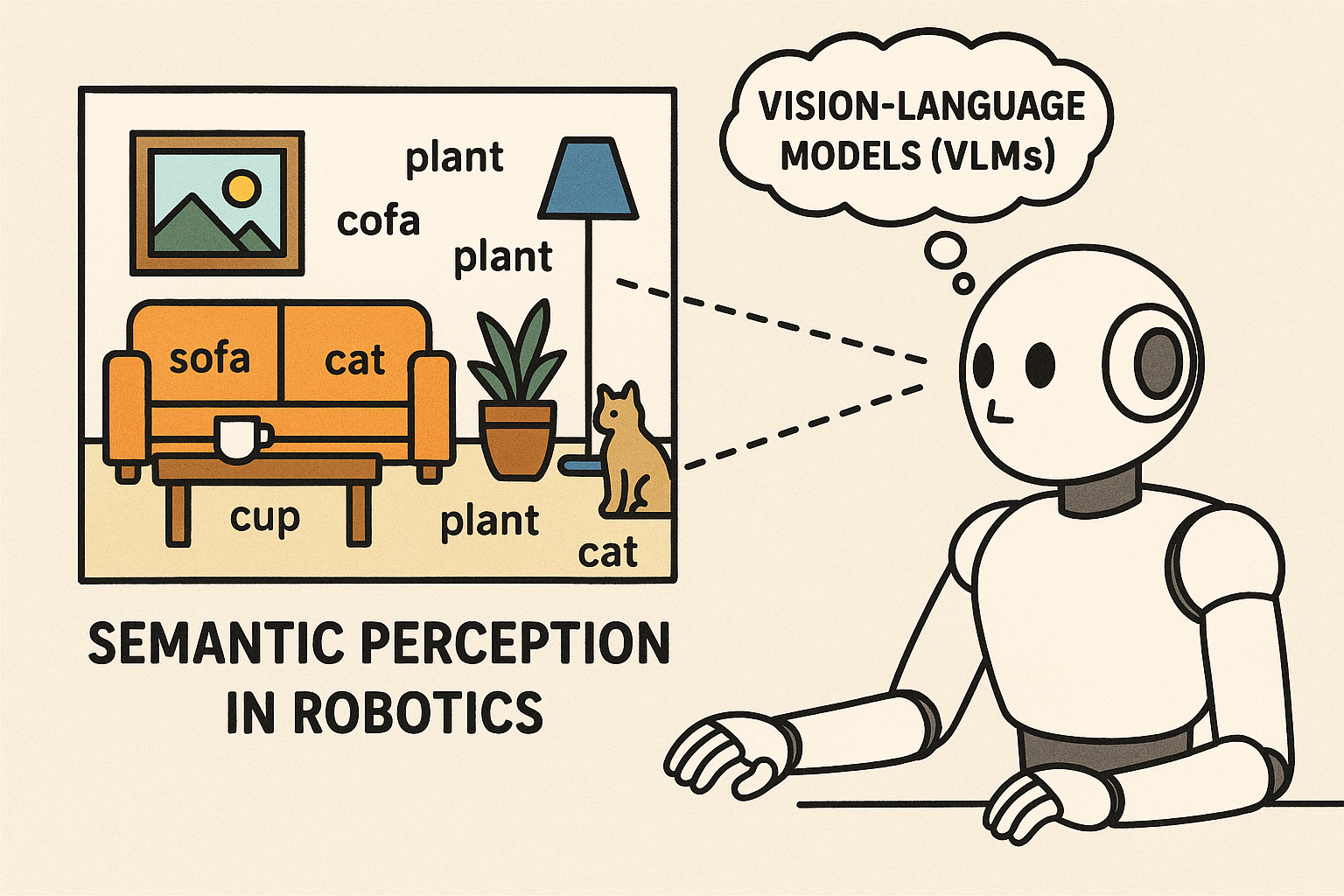
The Next Leap: From Sensor Fusion to Semantic Perception in Robotics
Exploring the paradigm shift from traditional LiDAR-camera sensor fusion to semantic perception powered by vision-language models. Discover how VLMs are enabling robots to interpret scenes through human-like understanding, moving from geometric reconstruction to contextual reasoning and intent recognition.
12 min read
Technical Analysis
Perception Survey