Foundation Models in Robotics: Current Developments, Challenges, and Future Directions
Foundation models enable robots to understand natural language instructions and perform complex manipulation tasks across diverse environments
Introduction
The field of robotics is experiencing a transformative moment analogous to the breakthrough periods in natural language processing and computer vision. Foundation models—large-scale neural networks trained on diverse datasets to capture broad patterns and capabilities—have demonstrated remarkable success in language (GPT-4, PaLM) and vision (CLIP, DALL-E) domains. Now, researchers are successfully adapting these paradigms to robotics, creating systems that can understand natural language instructions, perceive complex visual scenes, and execute sophisticated manipulation tasks with unprecedented generalization capabilities.
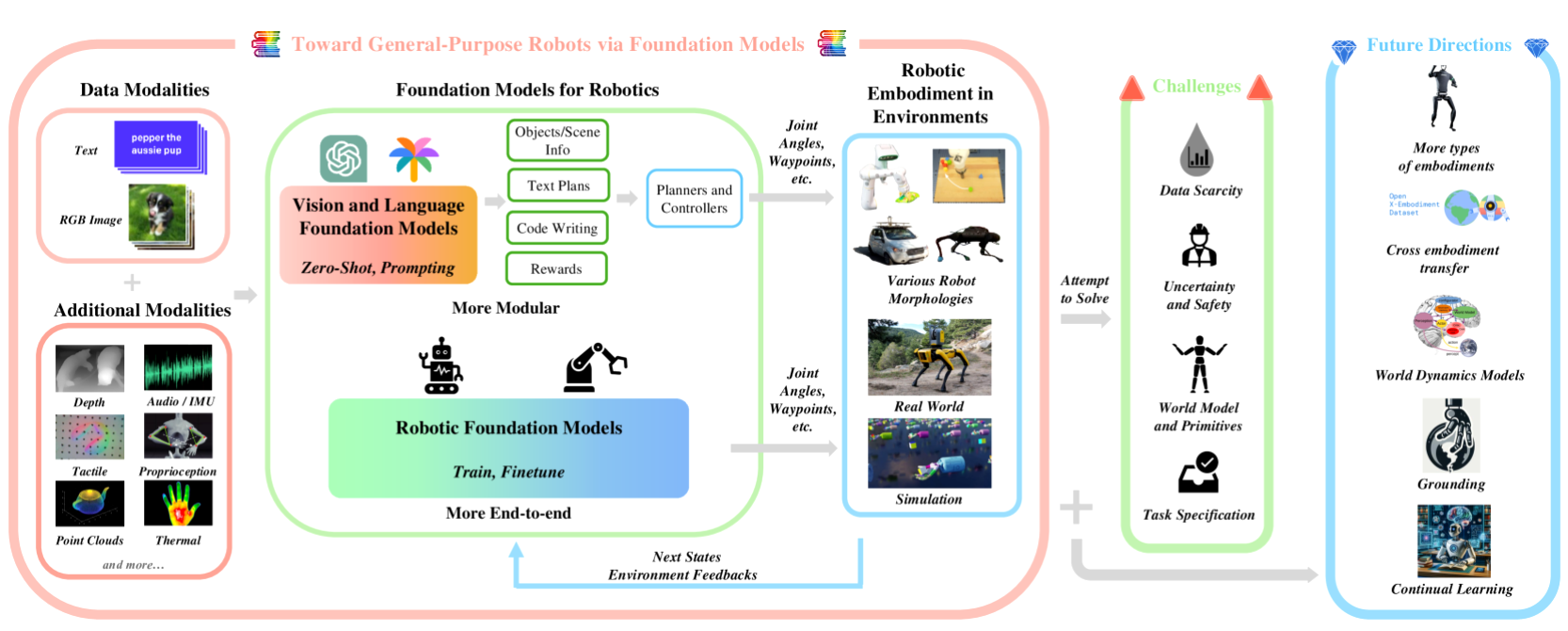
This comprehensive survey examines the current landscape of robotics foundation models, analyzing core challenges including generalization across tasks and embodiments, data scarcity, computational requirements, task specification methods, and safety considerations. We'll explore state-of-the-art architectures including RT-1/RT-2, PaLM-E, RoboCat, and emerging multi-modal systems, while highlighting promising research directions and critical gaps in the field.
Our discussion follows the taxonomy proposed by Firoozi et al. (2023), distinguishing between systems that apply existing foundation models to robotics tasks versus those that develop robotics-specific foundation models from the ground up—a distinction that has become fundamental to understanding the current research landscape.
"Foundation models are transforming robotics from task-specific automation to general-purpose intelligent agents capable of understanding, reasoning, and adapting to complex real-world environments."
Technical Background and Taxonomy
🏗️ Foundational Architecture
Foundation models in robotics represent a fundamental shift from task-specific algorithms to general-purpose AI systems built on transformer architectures and trained on massive, diverse datasets. These models demonstrate emergent capabilities including zero-shot generalization, in-context learning, and multi-modal reasoning that enable them to handle previously unseen robotic scenarios.
Two Approaches to Foundation Models in Robotics
Current research approaches can be categorized into two primary methodologies:
Foundation Models in Robotics (FMRs)
Pre-trained foundation models (VFMs, VLMs, LLMs) adapted for robotics applications through fine-tuning, prompting, or API integration. Examples include using GPT-4V for robotic perception or CLIP for object recognition.
Robotics Foundation Models (RFMs)
Models trained specifically on robotics data from the ground up, incorporating robot-specific inductive biases and embodiment awareness. Examples include RT-1/RT-2, RoboCat, and specialized manipulation transformers.
🔧 Core Capabilities
- Vision-Language-Action (VLA) Integration: Unified processing of visual observations, natural language instructions, and motor commands through shared transformer backbones
- Multi-Modal Reasoning: Cross-modal attention mechanisms enabling grounding of language in visual perception and action space
- Few-Shot Task Adaptation: Meta-learning capabilities allowing rapid adaptation to new tasks with minimal demonstration data
- Embodiment Transfer: Generalization across different robot morphologies and action spaces through learned representations
- Compositional Understanding: Decomposition of complex instructions into executable sub-tasks through hierarchical planning
Key Architectural Innovations
Transformer-based Architectures: Most robotics foundation models leverage transformer architectures due to their ability to handle variable-length sequences, attention mechanisms for multi-modal fusion, and scalability to large datasets.
Multi-Modal Tokenization: Advanced tokenization strategies that convert images, text, and actions into unified token spaces, enabling joint training and inference across modalities.
Hierarchical Planning: Integration of high-level planning modules with low-level control through learned skill primitives and temporal abstraction mechanisms.
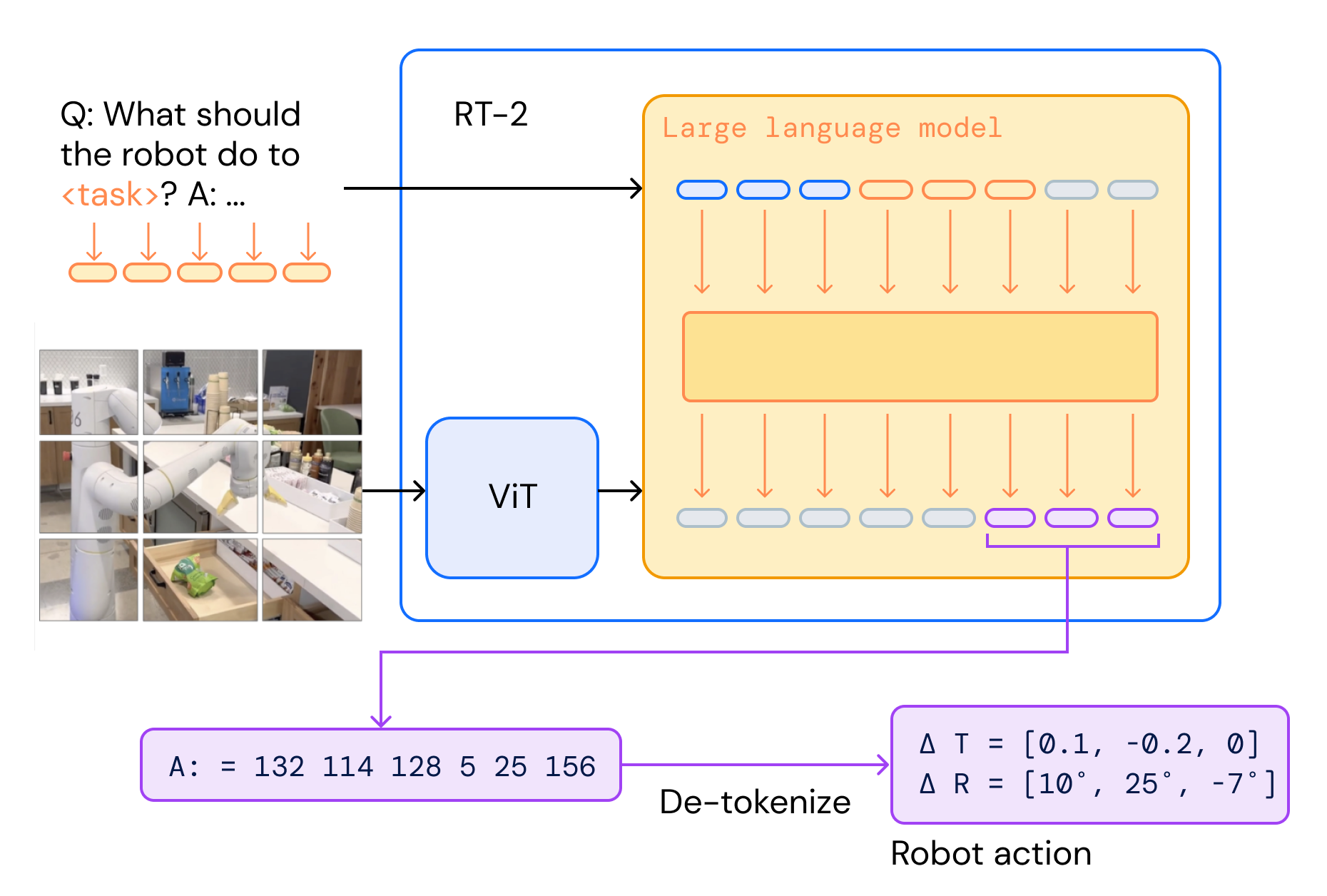
RT‑2 architecture: co‑fine‑tuning vision-language models with robot action tokens.
State-of-the-Art Models and System Architectures
Robotics Transformer Family (RT-1, RT-2, RT-X)
RT-1 (Robotics Transformer 1): Pioneered the VLA architecture by training a 35M parameter transformer on 130K robot demonstrations. Uses FiLM conditioning to integrate language instructions with visual observations, outputting discretized action tokens for manipulation tasks.
RT-2 (Robotics Transformer 2): Scales to 55B parameters by co-training on both robotics data and web-scale vision-language data. Demonstrates emergent capabilities including reasoning about object properties, spatial relationships, and novel object categories not seen in robotics training data. Achieves 62% success rate on novel tasks compared to RT-1's 32%.
RT-X: Open-source dataset and model suite enabling cross-embodiment learning across multiple robot platforms, demonstrating that foundation models can generalize across different robot morphologies and action spaces.
PaLM-E: Embodied Multimodal Language Model
A 562B parameter model that integrates PaLM's language capabilities with visual encoders and robotics data. Key innovations include:
- Sensor Integration: Processes RGB images, object detection outputs, and even ViT features as sentence tokens
- Multi-Task Training: Jointly trained on language, vision, and robotics tasks to maintain general capabilities while acquiring embodied intelligence
- Long-Sequence Reasoning: Handles complex, multi-step instructions requiring temporal reasoning and planning
SayCan: Grounding Language in Robotic Affordances
Combines large language models with value functions to ground high-level instructions in robot capabilities. Architecture consists of:
- Task Planning: LLM generates candidate action sequences for complex instructions
- Affordance Scoring: Pre-trained value functions score feasibility of each action
- Execution: Highest-scoring plans are executed using learned manipulation policies
RoboCat: Self-Improving Multi-Embodiment Agent
DeepMind's RoboCat represents a significant advance in multi-embodiment learning and self-improvement:
- Multi-Embodiment Training: Trained on data from multiple robot arms with different action spaces and kinematics
- Self-Improvement Loop: Generates additional training data through self-supervised practice, improving performance iteratively
- Few-Shot Adaptation: Demonstrates ability to adapt to new robot embodiments with just 100-1000 demonstrations
- Scaling Benefits: Performance improves with both model size and training data diversity
Emerging Models and Architectures
VoxPoser: Combines LLMs with 3D scene understanding for spatial reasoning and manipulation planning in cluttered environments.
PerAct: Employs 3D point cloud transformers for precise 6-DOF manipulation, demonstrating the importance of spatial representations in foundation models.
CLIP-Fields: Integrates CLIP embeddings with neural radiance fields for semantic scene understanding and manipulation planning.
GPT-4V Integration: Recent work demonstrates using GPT-4V's visual reasoning capabilities for robotic task planning and execution monitoring.
Key Applications Transforming Industries
Industrial Automation
Foundation models enable robots to adapt to new manufacturing processes, handle diverse components, and optimize production workflows without extensive reprogramming.
Healthcare Robotics
Medical robots powered by foundation models can assist in surgery, patient care, and rehabilitation with unprecedented precision and adaptability.
Service Robotics
Home and service robots can understand natural language commands, navigate complex environments, and perform household tasks with human-like understanding.
Autonomous Vehicles
Self-driving cars leverage foundation models for better scene understanding, decision-making, and human-robot interaction in complex traffic scenarios.
Core Challenges in Robotics Foundation Models
Current research identifies five fundamental challenges that must be addressed for the successful deployment of foundation models in robotics. These challenges represent active areas of investigation with significant implications for the field's future development:
1. Generalization Across Tasks and Embodiments
Challenge: Achieving generalization across diverse robotic tasks, environments, and hardware platforms while maintaining task-specific performance.
- Task Distribution Shift: Models trained on pick-and-place tasks struggle with manipulation requiring different skill compositions
- Embodiment Transfer: Action spaces and kinematics vary significantly across robot platforms, requiring learned representations that abstract over hardware specifics
- Environmental Variability: Lighting conditions, object textures, and scene layouts create domain gaps that challenge model robustness
Current Solutions: Multi-task training, domain randomization, meta-learning approaches, and embodiment-agnostic action representations.
2. Data Scarcity and Quality
Challenge: Robotics data is orders of magnitude more expensive to collect than language or vision data, with quality requirements for successful task execution.
- Scale Gap: While language models train on trillions of tokens, largest robotics datasets contain millions of trajectories
- Collection Complexity: Requires physical robots, human demonstrators, and controlled environments, limiting data diversity
- Temporal Dependencies: Robotics data involves temporal sequences with complex state-action dependencies
- Multi-Modal Alignment: Synchronizing vision, language, and action data across different sampling rates and modalities
Current Solutions: Synthetic data generation, simulation-to-real transfer, data augmentation techniques, and cross-embodiment learning.
3. Model Requirements and Computational Constraints
Challenge: Balancing model capacity with real-time performance requirements and deployment constraints on robotic hardware.
- Latency Requirements: Control loops typically require 10-100Hz update rates, limiting model inference time
- Edge Deployment: Many robots operate without reliable cloud connectivity, requiring on-device inference
- Power Constraints: Mobile robots have limited battery capacity, constraining computational resources
- Memory Bandwidth: Large models require substantial memory access, challenging embedded deployment
Current Solutions: Model distillation, quantization, efficient architectures (MobileNet, EfficientNet), and hierarchical control with offline planning.
4. Task Specification and Human-Robot Interaction
Challenge: Developing intuitive and robust interfaces for specifying complex tasks and enabling natural human-robot collaboration.
- Ambiguity Resolution: Natural language instructions often contain ambiguities requiring contextual understanding and clarification
- Multi-Modal Communication: Humans communicate through speech, gestures, and demonstrations requiring integrated understanding
- Adaptation to User Preferences: Different users have varying preferences for task execution styles and interaction modalities
- Contextual Grounding: Understanding references to objects, locations, and actions within dynamic environments
Current Solutions: Multi-modal fusion architectures, interactive learning, user modeling, and clarification dialog systems.
5. Uncertainty Quantification and Safety
Challenge: Ensuring safe operation in dynamic, uncertain environments while providing reliable uncertainty estimates for critical decisions.
- Distributional Shift: Foundation models may encounter scenarios outside their training distribution requiring robust uncertainty quantification
- Safety-Critical Operation: Physical robots can cause harm to humans or property, requiring extremely high reliability standards
- Verification and Validation: Proving safety properties of large neural networks remains an open research challenge
- Failure Recovery: Systems must detect failures and recover gracefully without human intervention
Current Solutions: Bayesian neural networks, ensemble methods, conformal prediction, safe reinforcement learning, and formal verification techniques.

Isaac GR00T N1 humanoid — a real-world robotics embodiment of foundation models
Promising Research Directions and Future Developments
Multi-Modal Foundation Models
The integration of multiple sensory modalities into unified foundation models represents a critical research direction for creating more robust and capable robotic systems:
- Vision-Language-Audio-Tactile Integration: Developing architectures that can seamlessly process and reason across visual, linguistic, auditory, and tactile inputs
- Cross-Modal Attention Mechanisms: Advanced attention architectures that can ground language in visual scenes while incorporating haptic feedback
- Temporal Multi-Modal Fusion: Handling temporal dependencies across different modalities with varying sampling rates and latencies
- Unified Representation Learning: Learning shared representations that capture cross-modal correspondences and enable transfer between modalities
Current Progress: GPT-4V demonstrates vision-language understanding for robotics, while models like ImageBind show promise for unified multi-modal representations.
🧠 In-Context Learning and Few-Shot Adaptation
Enabling robots to rapidly adapt to new tasks through in-context learning represents a fundamental shift toward more flexible and generalizable robotic systems:
- Demonstration-Based Learning: Systems that can learn new manipulation skills from just a few human demonstrations or video examples
- Contextual Skill Composition: Combining existing skills in novel ways based on contextual understanding of task requirements
- Meta-Learning Architectures: Models that learn to learn, adapting their learning strategies based on task structure and available data
- Interactive Learning: Systems that can ask questions, seek clarification, and iteratively refine their understanding through human feedback
Key Challenges: Balancing rapid adaptation with stable performance, handling distribution shift, and maintaining safety during learning.
🤖 Embodiment-Agnostic Learning
Developing foundation models that can generalize across different robot embodiments and morphologies:
- Universal Action Representations: Learning action embeddings that abstract over specific robot kinematics and actuator configurations
- Morphology-Aware Networks: Architectures that explicitly model robot morphology and can adapt to new embodiments
- Sim-to-Real Transfer: Improved techniques for transferring policies learned in simulation to real-world robots with different characteristics
- Continual Learning: Systems that can learn new embodiments without forgetting previously acquired skills
Applications: Enabling a single model to control diverse robots from manufacturing arms to humanoid robots to aerial vehicles.
🌐 World Models and Predictive Learning
Developing foundation models that can learn and maintain internal models of the physical world:
- Physics-Informed Learning: Incorporating physical laws and constraints into model architectures for better generalization
- Causal Reasoning: Models that can understand cause-and-effect relationships in physical interactions
- Temporal Prediction: Long-horizon prediction capabilities for planning and decision-making
- Uncertainty Quantification: Reliable uncertainty estimates for model predictions to enable safe decision-making
Impact: Enabling robots to reason about consequences of actions, plan complex sequences, and operate safely in dynamic environments.
🤝 Human-Robot Collaboration
Foundation models are enabling more natural and effective human-robot collaboration through advanced interaction capabilities:
- Intent Recognition: Understanding human intentions through multimodal observation of speech, gestures, and actions
- Shared Mental Models: Developing common understanding between humans and robots about tasks and goals
- Adaptive Interaction: Personalizing robot behavior based on individual user preferences and expertise levels
- Natural Communication: Enabling robots to communicate through natural language, gestures, and other intuitive modalities
Applications: Collaborative manufacturing, assistive robotics, and co-working scenarios where humans and robots work as partners.
🔧 Self-Improving and Autonomous Learning Systems
Research into robots that can autonomously collect data, learn from experience, and continuously improve their performance:
- Autonomous Data Collection: Robots that can identify learning opportunities and collect targeted training data
- Online Learning: Continuous adaptation during deployment without requiring offline training phases
- Failure Analysis: Systems that can analyze failures, understand their causes, and update their behavior accordingly
- Curriculum Learning: Automated generation of learning curricula that progressively increase task complexity
Key Benefits: Reduced need for human supervision, improved performance over time, and adaptation to changing environments.
🔬 Evaluation and Benchmarking
Developing comprehensive evaluation frameworks for robotics foundation models:
- Standardized Benchmarks: Creating standardized evaluation protocols that can assess generalization across tasks and embodiments
- Real-World Evaluation: Moving beyond simulation to real-world testing in diverse, uncontrolled environments
- Long-Horizon Assessment: Evaluating performance on complex, multi-step tasks requiring sustained reasoning
- Safety and Reliability Metrics: Developing metrics that capture safety, robustness, and reliability in addition to task success
Importance: Rigorous evaluation is essential for advancing the field and ensuring reliable deployment of foundation models in robotics.
"The convergence of foundation models and robotics represents one of the most exciting frontiers in AI. We're moving from robots that execute pre-programmed tasks to intelligent agents that can understand, reason, and adapt to the complexities of the real world."— Vision for the Future of Robotics
The Road Ahead: Future Implications
As foundation models continue to evolve, we can expect to see:
Conclusion: A New Chapter in Robotics
Foundation models are ushering in a new era of robotics—one where machines can understand natural language, perceive complex environments, and adapt to novel situations with remarkable flexibility. While challenges remain, the rapid progress in this field suggests that the dream of truly intelligent, general-purpose robots is closer than ever.
As we stand at this technological inflection point, the collaboration between AI researchers, roboticists, and industry practitioners will be crucial in realizing the full potential of foundation models in robotics. The future promises robots that don't just follow instructions, but truly understand and interact with our world in meaningful ways.
📚 References
Survey Papers
[1] Firoozi, R., Ju, T., Zhao, T. Z., et al. (2023). Foundation Models in Robotics: Applications, Challenges, and the Future. arXiv preprint arXiv:2312.07843.
[2] Shah, D., Sridhar, A., Bhorkar, A., et al. (2023). Integrating Reinforcement Learning with Foundation Models for Autonomous Robotics: Methods, Challenges, and Opportunities. arXiv preprint arXiv:2311.08104.
Vision-Language-Action Models
[3] Brohan, A., Brown, N., Carbajal, J., et al. (2023). RT-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818.
[4] Brohan, A., Chebotar, Y., Finn, C., et al. (2022). RT-1: Robotics Transformer for Real-World Control at Scale. arXiv preprint arXiv:2212.06817.
[5] Driess, D., Xia, F., Sajjadi, M. S., et al. (2023). PaLM-E: An embodied multimodal language model. arXiv preprint arXiv:2303.03378.
Multi-Embodiment and Transfer Learning
[6] Bousmalis, K., Vezzani, G., Rao, D., et al. (2023). RoboCat: A self-improving generalist agent for robotic manipulation. arXiv preprint arXiv:2306.11706.
[7] Padalkar, A., Pooley, A., Jain, A., et al. (2023). Open X-Embodiment: Robotic Learning Datasets and RT-X Models. arXiv preprint arXiv:2310.08864.
Language Grounding and Planning
[8] Ahn, M., Brohan, A., Brown, N., et al. (2022). Do as I can, not as I say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691.
[9] Huang, W., Abbeel, P., Pathak, D., et al. (2023). VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models. arXiv preprint arXiv:2307.05973.
[10] Shridhar, M., Manuelli, L., Fox, D. (2022). PerAct: Perception-Action Causal Transformer for Multi-Task Manipulation. arXiv preprint arXiv:2209.05451.
Foundation Model Architectures
[11] Reed, S., Zolna, K., Parisotto, E., et al. (2022). A generalist agent. Transactions on Machine Learning Research.
[12] Team, G. R., Adler, J., Agarwal, R., et al. (2023). Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
[13] Radford, A., Kim, J. W., Hallacy, C., et al. (2021). Learning transferable visual models from natural language supervision. International conference on machine learning (ICML).
Safety and Uncertainty
[14] Kenton, Z., Everitt, T., Weidinger, L., et al. (2021). Alignment of Language Agents. arXiv preprint arXiv:2103.14659.
[15] Christiano, P. F., Leike, J., Brown, T., et al. (2017). Deep reinforcement learning from human feedback. Advances in neural information processing systems (NeurIPS).
Datasets and Benchmarks
[16] Mandlekar, A., Zhu, Y., Garg, A., et al. (2018). RoboTurk: A crowdsourcing platform for robotic skill learning through imitation. Conference on Robot Learning (CoRL).
[17] Ebert, F., Dasari, S., Quigley, A., et al. (2021). Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets. arXiv preprint arXiv:2109.13396.
[18] Yu, T., Quillen, D., He, Z., et al. (2019). Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. Conference on Robot Learning (CoRL).
Note: This blog post represents the state of the field as of late 2024. Given the rapid pace of development in foundation models for robotics, always check recent arXiv preprints and conference proceedings for the most current developments.